We began our project by wondering about autocomplete. It’s intimately familiar to anyone who has used Google and almost taken for granted: you begin typing and things you may be looking for are magically presented to you based on what you’ve entered so far. It’s powerful and useful, so it’s no surprise that there are many independent variations of autocomplete widely available.
Many of these solutions take time and effort to implement, are limited by data constraints in the front end, and often work off of a fixed set of suggestions as opposed to dynamically integrating user input and ranking suggestions, thereby missing some of the power that a Google-style autocomplete has.
Thus we were intrigued by the idea of an easy to implement autocomplete that any developer could use on any search field for their site with just a simple client side code snippet. Not only that, but a robust and fully featured autocomplete that dynamically crowd-sources user input and ranks it by popularity, improving suggestions over time, much like Google would.
This led us to ask the question, “how can we build a system that supports efficient prefix search in order to power a google-style autocomplete?” This question began a deep dive analysis into the data structures, algorithms, and system design, for what would ultimately become Prefixy.
What is Prefixy?
Prefixy is a hosted prefix search engine that powers autocomplete suggestions. It dynamically updates and ranks suggestions based on popularity. It is an easy to use service that can be used to set up powerful and adaptive autocomplete on any website with just a simple code snippet.
To get an idea of how it works on the frontend, try out the demo below. Notice that as you type, suggestions appear that you can select. Upon pressing Enter, your search is submitted, and depending on the popularity ranking of other suggestions, you may see your search appear higher in the list of suggestions the next time you type.
About us
We are a team of three software engineers, who developed this project remotely from across the country. We also happen to be looking for new work opportunities. Please don’t hesitate to reach out if we seem like a good fit for your team!
Let’s get into the story of how we built Prefixy. The goal of this post is communicate the following takeaways:
What we prioritized during the research and development stages of the project
How we thought about tradeoffs as we designed and built a system from scratch
How we evaluated data structures, algorithms, and data stores for the system
How we built a system with the flexibility to scale as we get more users
Hopefully some of the process and lessons learned we share here will be of value to you in your own project!
Terminology
Before we go further, there is certain terminology we used as we built this project that will be helpful in understanding the rest of this post. Consider the following definitions along with the diagram below:
prefix - What the user has typed so far.
completions - All possible ways a given prefix can be completed in order to form a valid word or phrase.
suggestions - The top ranked completions, which will be presented to the user.
score - An integer representing the popularity of a given completion.
selection - The suggestion that the user chooses or a new completion that the user submits.
Design goals
Now that we’re on the same page as far as the terminology, let’s get into the design goals we had for our system.
Requirements
One of the most important requirements is that we provide lightning fast reads. A user of an autocomplete expects that suggestions will appear nearly instantaneously as they type. If they don’t, the autocomplete is no longer useful. For instance, Facebook found that in order for an autocomplete to be useful, it needs to return suggestions in less than 100 milliseconds.
The other major requirement is that suggestions need to be dynamically ranked and relevant to the user. When a user types a prefix, the most popular suggestions should be shown to them. Over time, the ranking of suggestions should change as their popularity changes.
Implications & approach
The first implication of the requirements is that we need to prioritize the speed of reads. When we analyze data structures, algorithms, and persistence strategies, we need to make sure that the choices we make always support fast reads.
The other implication is that we need some sort of ranking algorithm. We need a way to determine which completions are the most popular for a given prefix and thereby have to be able to update the scores of completions over time.
Data structures & algorithms
Long before any line of code was written, we wanted to determine the best data structures and algorithms to support our requirements. We dedicated significant time for this analysis, knowing that it was a key component in achieving our goals.
As we compared different options, there were three main measurements we needed to keep in mind for Big O:
N - the number of keys/nodes (e.g. prefixes) in our dataset
K - the number of completions stored for a given prefix
L - the length of the prefix we are looking up
To walk through the different data structures, we’ll use the following completions and corresponding scores to help visualize these data structures in our diagrams:
Naive hash
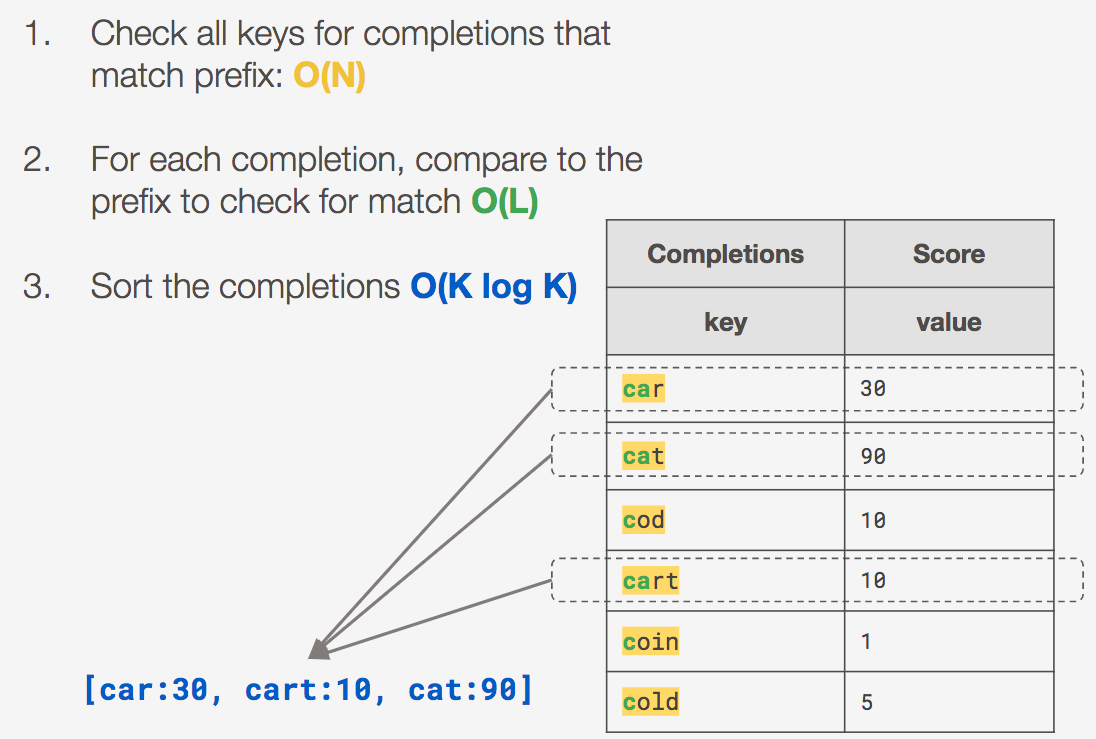
The first data structure we considered was a hash table, in which we store all of the completions as keys and their scores as values.
First, we analyzed the time complexity of searching for completions for a given prefix with this approach.
Let’s say we’re searching for all completions that match the prefix “ca”:
This means the time complexity of search would be O(NL) + O(K log K).
The main bottleneck of this approach is the O(N) check of all keys. As our data grows in size, this is far too slow to support our requirements. (Imagine how quickly the number of keys will grow when the service is powering thousands of autocompletes, capturing any new completions entered!)
In terms of space, the naive hash is reasonable. The space consumed would be equal to the number of completions (N) plus the extra space consumed in order to accommodate the hash’s load factor.
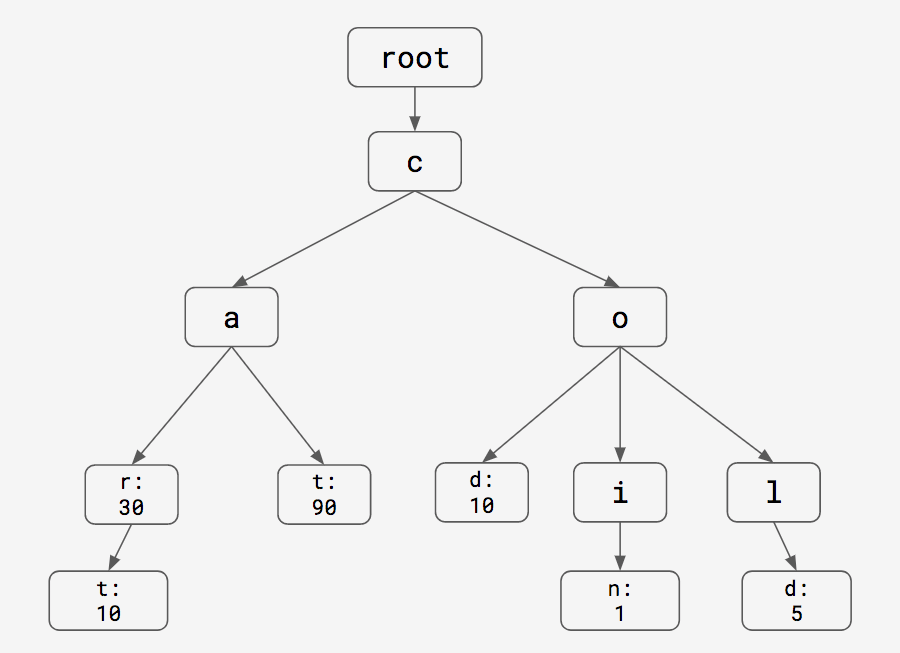
Naive trie
The next data structure we considered was a trie. Tries were interesting to us from the get-go as they happen to be a natural fit for prefix search, as it allows for O(L) lookup of a prefix (L being the length of the prefix!). It also takes up less space than the naive hash, as all descendents of a given node share the node as a common prefix. We also don’t need to accommodate extra space for the hash’s load factor.
Visualized slightly differently, we can see how each node builds on its parent node:
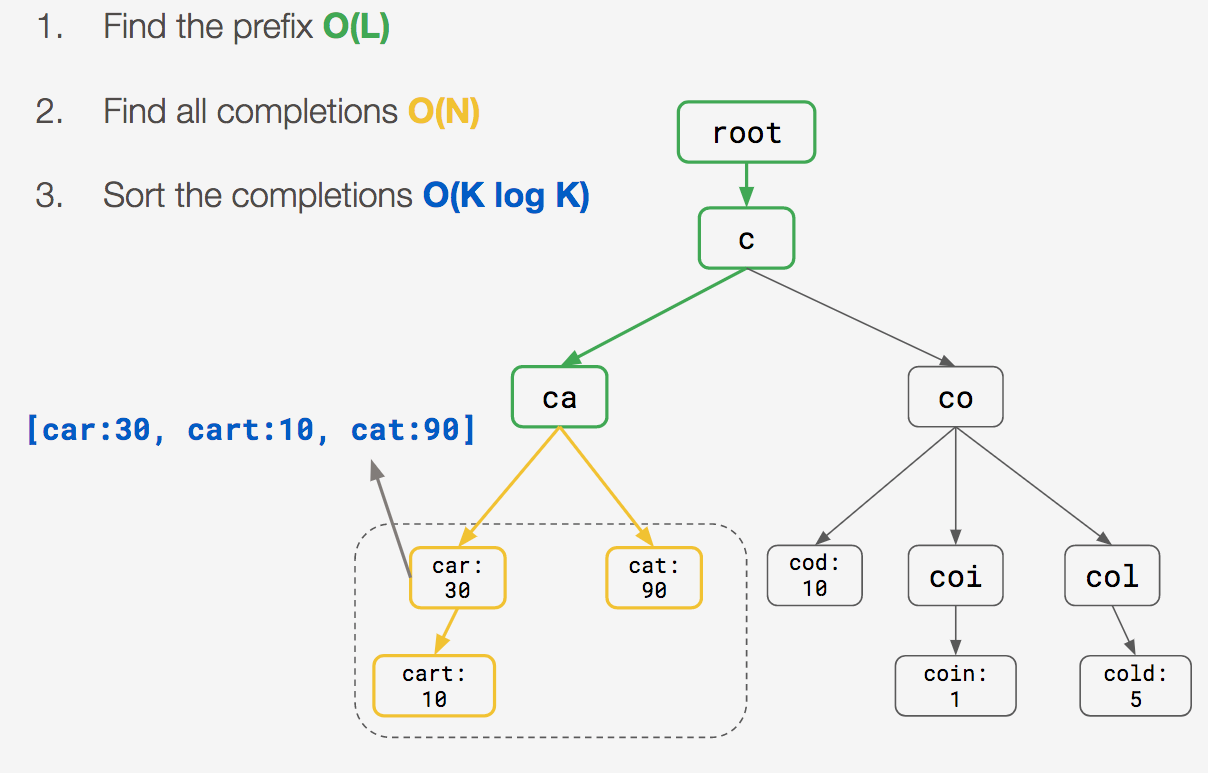
Looks like a good choice so far, but how would searching for completions work? Let’s look at the steps required for our “ca” prefix search:
Therefore the total time complexity for search is O(L) + O(N) + O(K log K), with the bottleneck again being O(N).
You may be wondering, “why it is O(N) for finding the completions?” This is because after finding the prefix node, you still have to traverse down to all of its child nodes to find its completions. Although often this would technically not be every node, as the longer the prefix, there are ostensibly fewer child nodes to traverse down to.
Still being stuck on O(N), we asked ourselves, “how do we remove the O(N) bottleneck from search?”
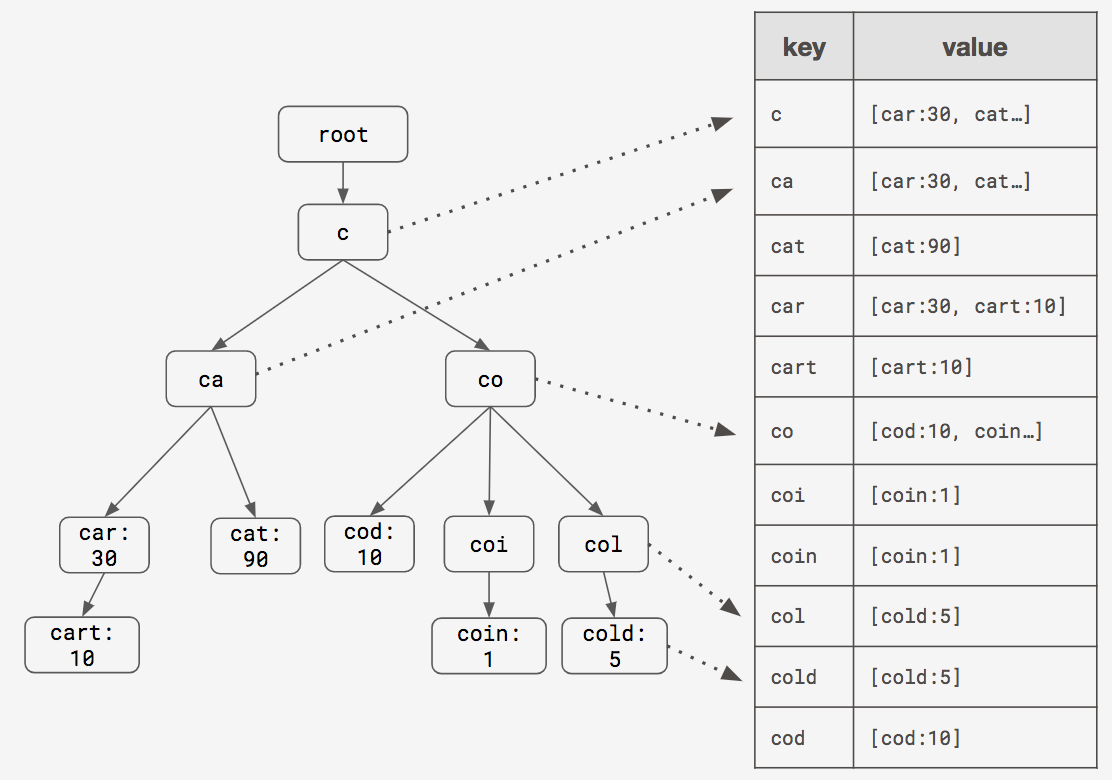
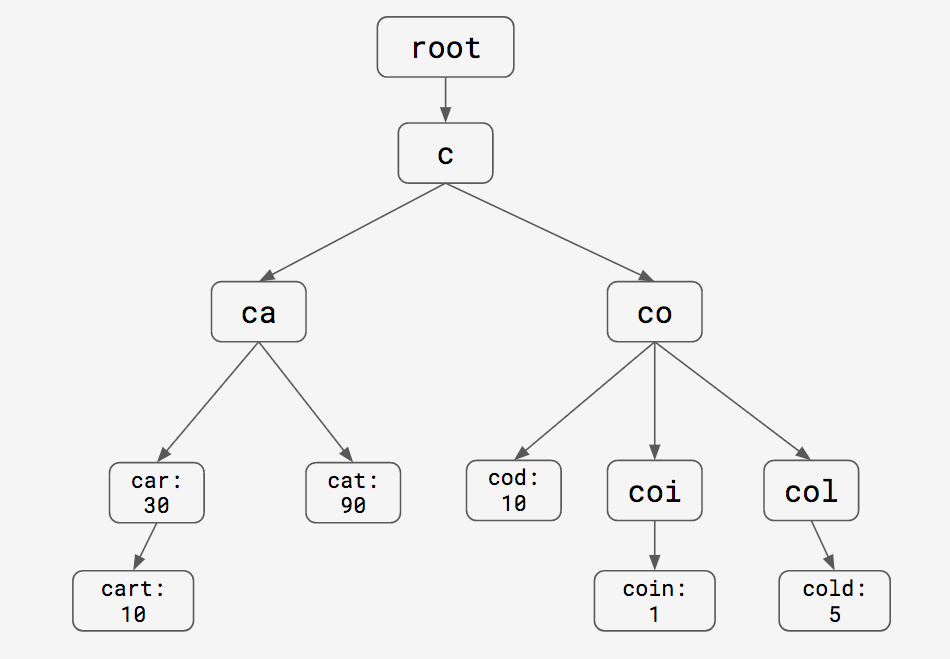
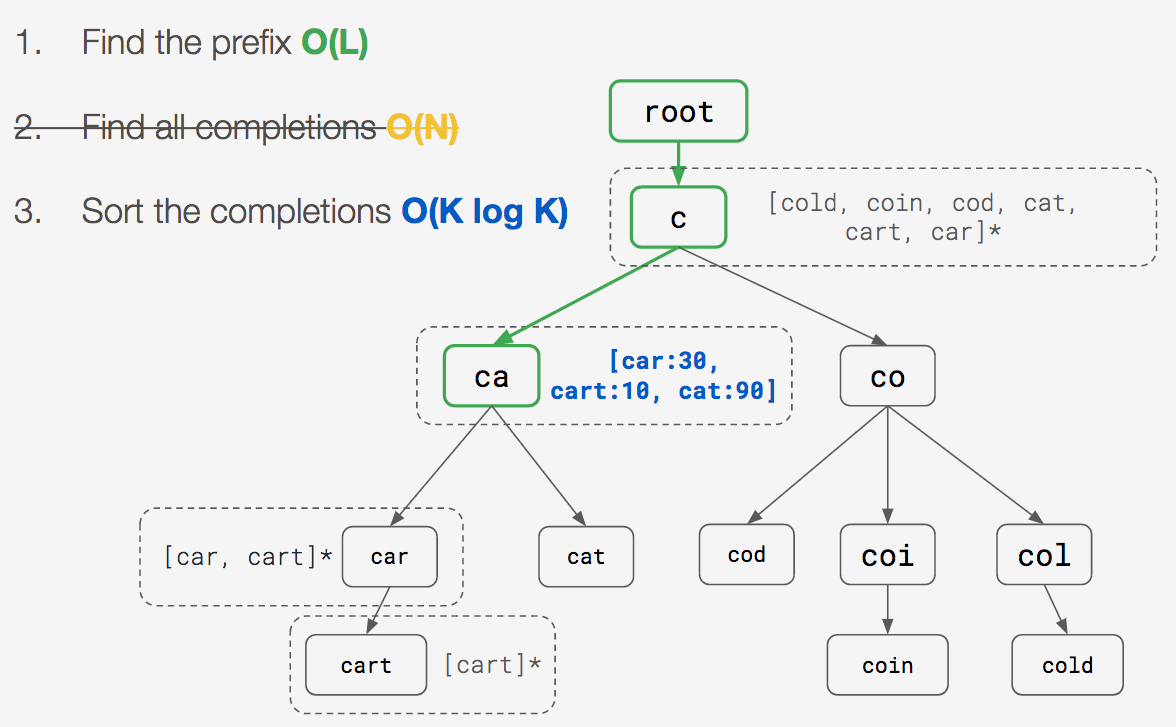
Storing completions in the trie
We realized that if we stored all of the completions for a given prefix in its node, we would no longer have to traverse to find all of the completions, thereby effectively eliminating the O(N) bottleneck.
Now, it takes just two steps to get the completions for a prefix:
*some scores omitted for presentation purposes
The time complexity is now significantly better, as it is no longer bottlenecked by the N, but this does come at a cost. We consume more space duplicating the completions for each prefix and require more writes to keep our completions up to date. But since speed is our priority, this is a trade off we are happy to make.
But can we do better than this? As you’re about to see, there are indeed further optimizations we can make that will improve time and space complexity significantly.
Holding L constant
There are diminishing returns to storing longer and longer prefixes. We can reasonably limit the max length of prefixes we store. Take for example the following completion:
“Tyrannosaurus Rex lived during the late Cretaceous period.”
We can reasonably expect that very few people will type a very long prefix such as:
“Tyrannosaurus Rex lived during the late C”
Instead, it’s much more likely that a user would type “Tyranno” or “Tyrannosaurus Rex l” and then choose a suggestion. Therefore, we can safely put a limit on the length of prefixes we store. We can set this limit to a reasonable amount like 20 characters.
This has two benefits. For one, we save space because we don’t have to store prefixes longer than the limit and the completions associated with those superfluous prefixes. The second and primary benefit, is that now the O(L) time to find the prefix effectively becomes constant O(1) time. And this is true because L will never be more than the constant limit.
Holding K constant
Similarly, there are diminishing returns to storing more and more completions for a given prefix. Remember that the user of an autocomplete will only see a small subset (what we call suggestions) of all of the completions for a given prefix. An autocomplete will normally display only around 5 to 10 of the most popular suggestions for a prefix.
So we really only need to store enough completions in order to enable accurate popularity ranking. We will get into the nitty gritty of the ranking algorithm we use later. For now, trust that storing around 50 completions for a given prefix is accurate enough for our needs.
Having a bucket limit on the number of completions we store for a prefix saves us space. But more importantly, the O(K log K) sorting time effectively becomes constant O(1) time. This holds because K will never grow larger than 50.
So by holding L and K constant, we now have effectively improved from O(L) + O(K log K) to O(1) + O(1). This reduces to O(1) time complexity for search! This now looks like a great data structure for our needs.
Prefix hash tree
There’s one last optimization we can make. We can map the trie’s prefixes with the completions stored at each node to a hash in a data structure that has been referred to as a Prefix Hash Tree (our confidence in this approach was bolstered by this paper which used utilized this to distribute a trie).
Basically, we map every node of the trie to a key in a hash. We also map the completions stored at that node to that key’s value.
The prefix hash tree gives us a few advantages over the trie. We can access any prefix in a single step O(1). But more importantly for our needs, the key/value structure is easy to implement in a NoSQL data store (we’ll get to why that’s beneficial soon!).
Again, we trade space for time. The hash takes up more space than the trie. This is because we lose the trie’s ability to share common characters of prefixes. We also need to allocate more space now to maintain the hash’s load factor. However, we are willing to take up more space for the previously mentioned advantages, as our priority is speed of reads.
In some ways, it may seem like we’re going back to the first naive hash solution we initially considered and immediately rejected. But the prefix hash tree is a much more sophisticated implementation when compared to the naive hash solution. Unlike the naive hash, the prefix hash tree meets our performance requirement for speed of reads.
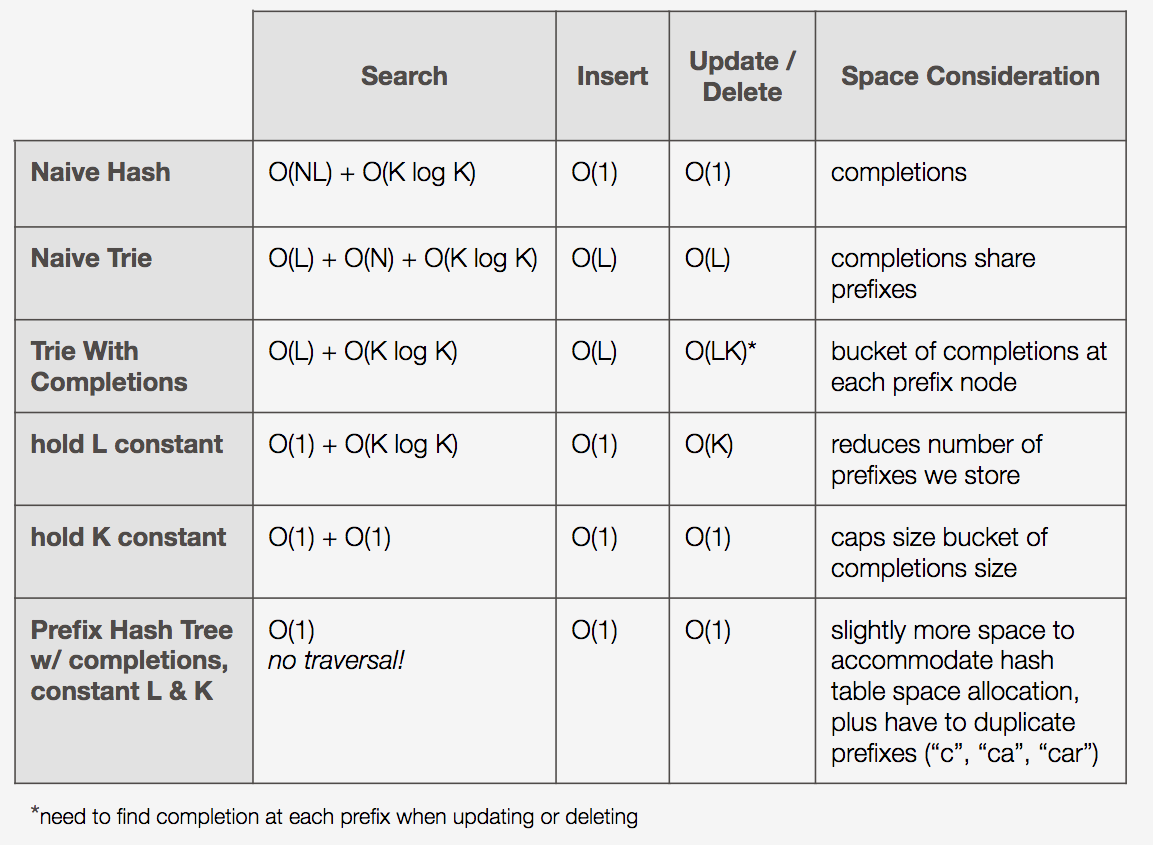
The following table summarizes our data structure analysis:
Enter Redis
As we mentioned, one of the benefits of the prefix hash tree is that it can easily map to a key/value NoSQL database. In our case, we chose to use Redis. Redis is a great match for our requirements for several reasons.
First of all, it is an entirely in-memory database. This means it can perform reads and writes much faster than a hard-disk data store. This is great for our use case, since fast reads are a priority for us.
Secondly, Redis provides us with a variety of native in-memory data structures. So we can store prefixes as Redis keys. The key’s value will be that prefix’s completions, which we can store in one of these native in-memory data structures. But which Redis data structure should we use to store completions?
Comparing Redis data structures
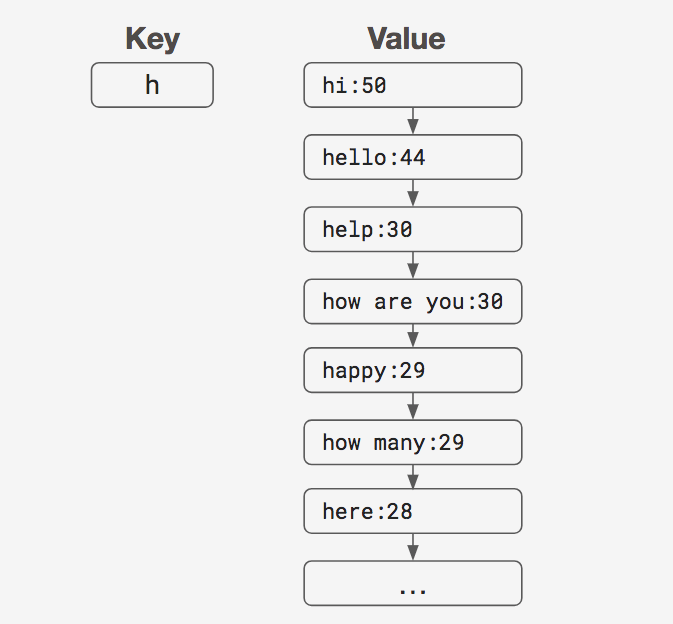
List
To store completions, the first Redis data structure we considered using was the list. A list in Redis is a doubly-linked list, in which each list node holds a string. With a doubly-linked list, we can access the head node or tail node in O(1) time. However, accessing other nodes takes O(K) time, where K is the number of completions for a given prefix.
Because each list node can only hold a string, we would need to store the score of the completion as part of the completion string.
One key function of our system is search (to get the suggestions for a prefix). Another key function is increment (to increase the score of a completion). Let’s examine how each of these functions would work if we choose the list data structure.
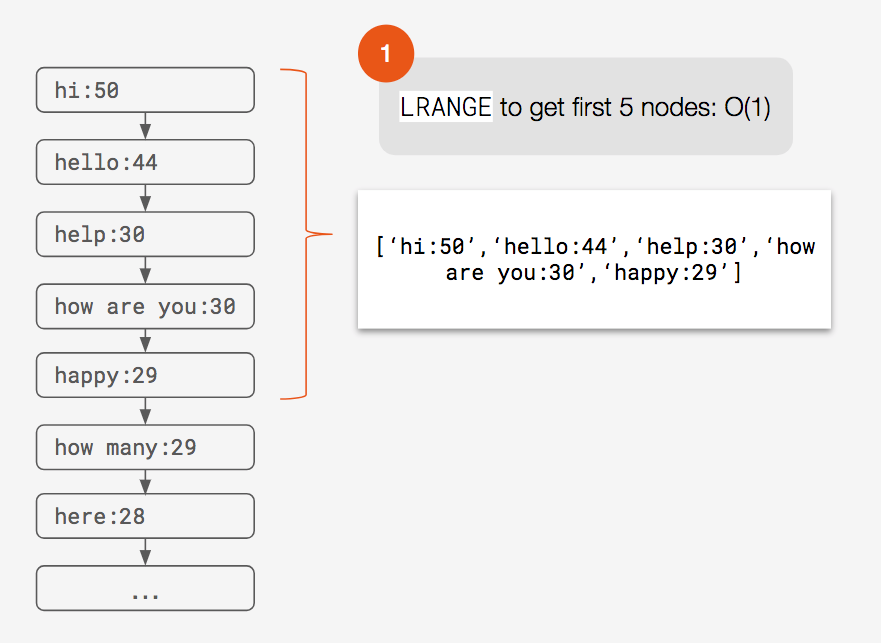
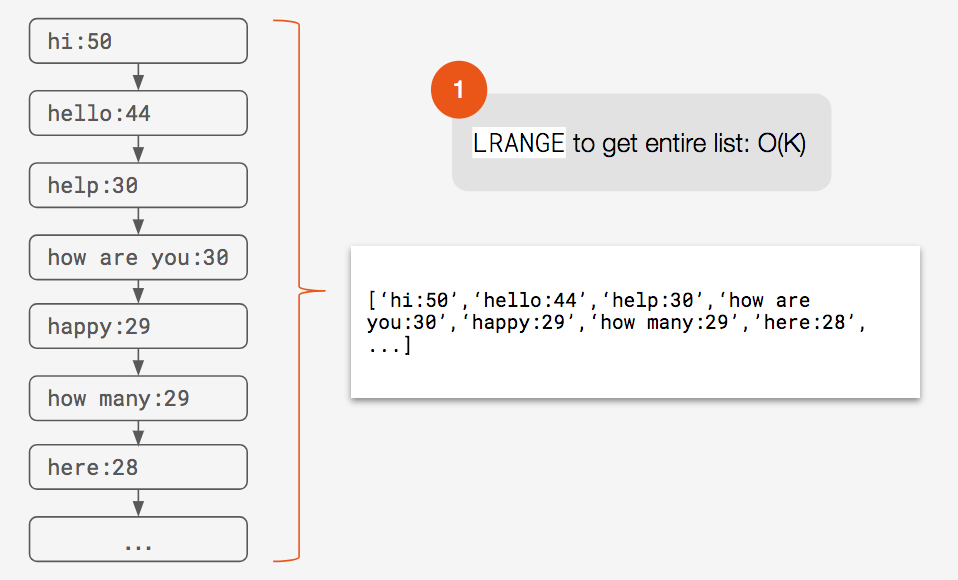
Search is quite straightforward with a list. In order to get the top suggestions for a given prefix, all we do is issue a single Redis LRANGE command. As long as we keep each list sorted, the top suggestions will always be at the head of a list. This means that we can access any prefix’s suggestions in O(1) time.
The increment logic, on the other hand, is quite cumbersome. It requires the following steps:
Issue LRANGE command to get the entire list O(K)
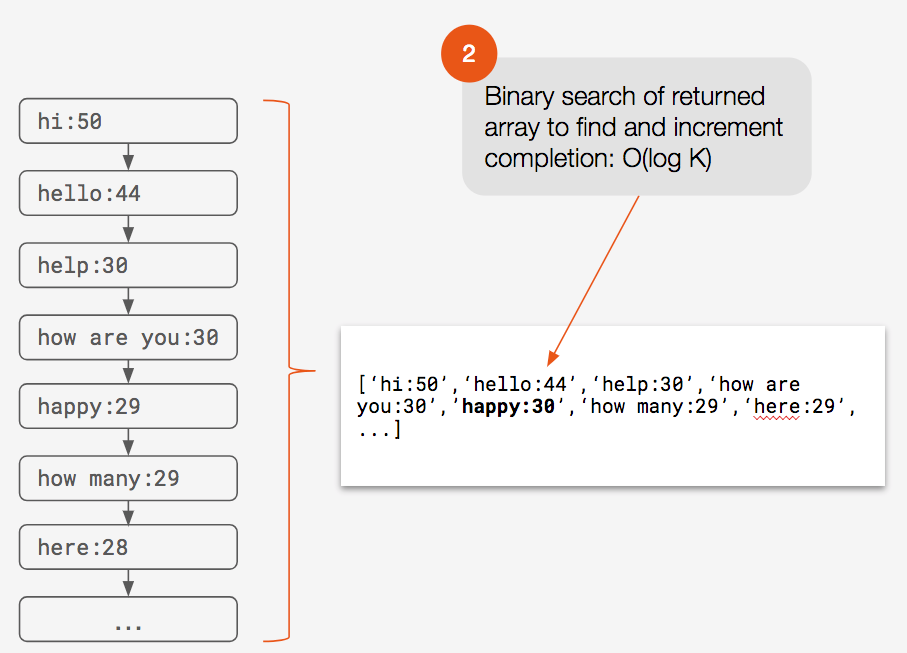
Binary search of returned array to find and increment completion: O(log K)
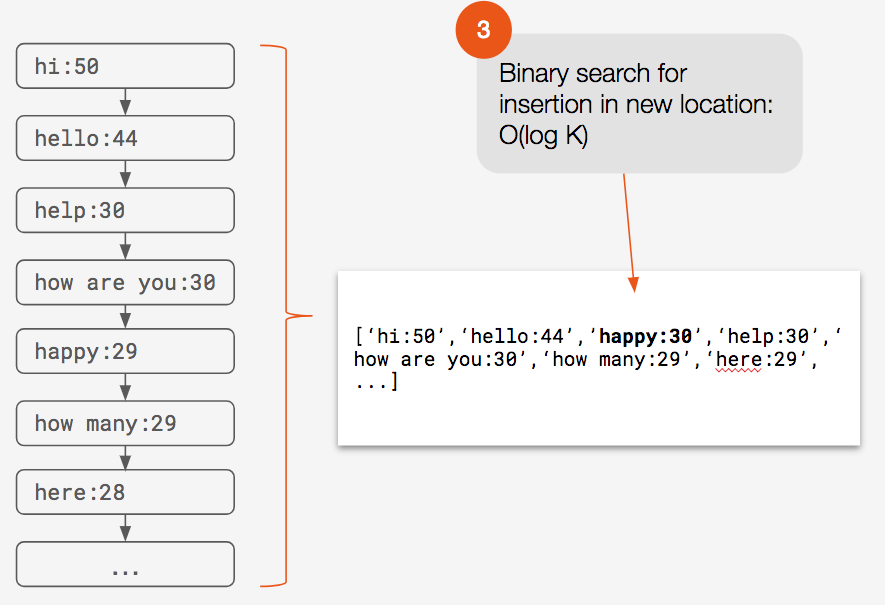
Binary search to find the completion’s correct new position: O(log K)
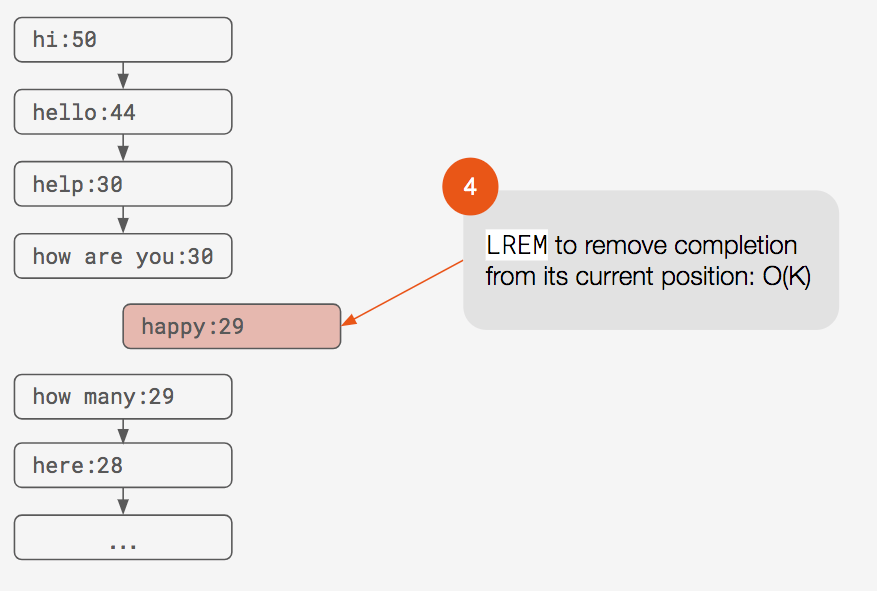
LREM to remove completion from its current position: O(K)
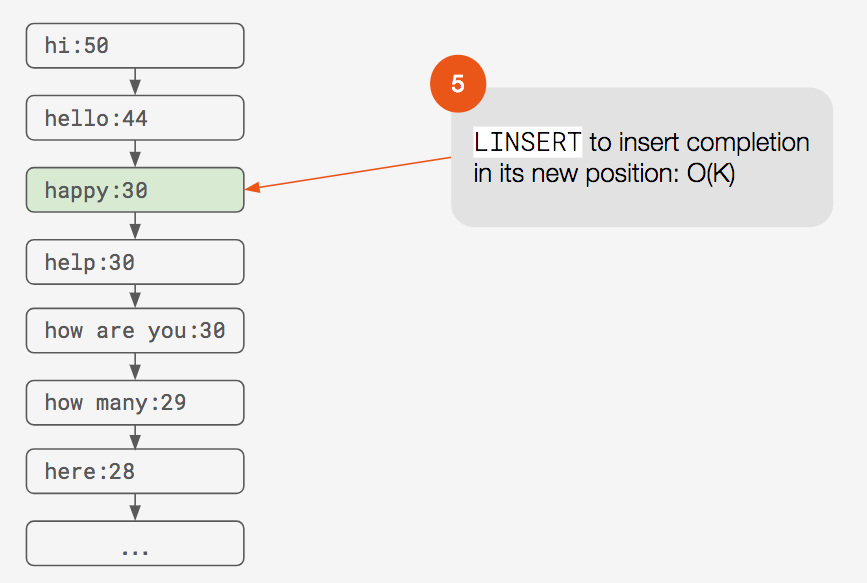
LINSERT to insert completion in its new position: O(K)
There are several disadvantages to this algorithm. The overall time complexity is O(K), and requires at least two round trips to Redis. The algorithm requires a large payload in the first request, as we need to retrieve the entire list. We need to do the sorting in our application, rather than in the database. There is no uniqueness guarantee for our data, which we need in order to maintain accurate scores. And we may run into concurrency issues with this many steps for the update logic.
So while we like the O(1) search the list offers, the list does not provide us with efficient updating.
Sorted set
Next, we considered using the Redis Sorted Set for storing completions. The sorted set is a collection of items. Each item consists of a string and its corresponding score. Items in the sorted set maintain order by score. Items with the same score are sorted lexicographically. Additionally, uniqueness of values is maintained. All of these features are a very good match for the structure of our data!
Now let’s examine how each of our key functions would work.
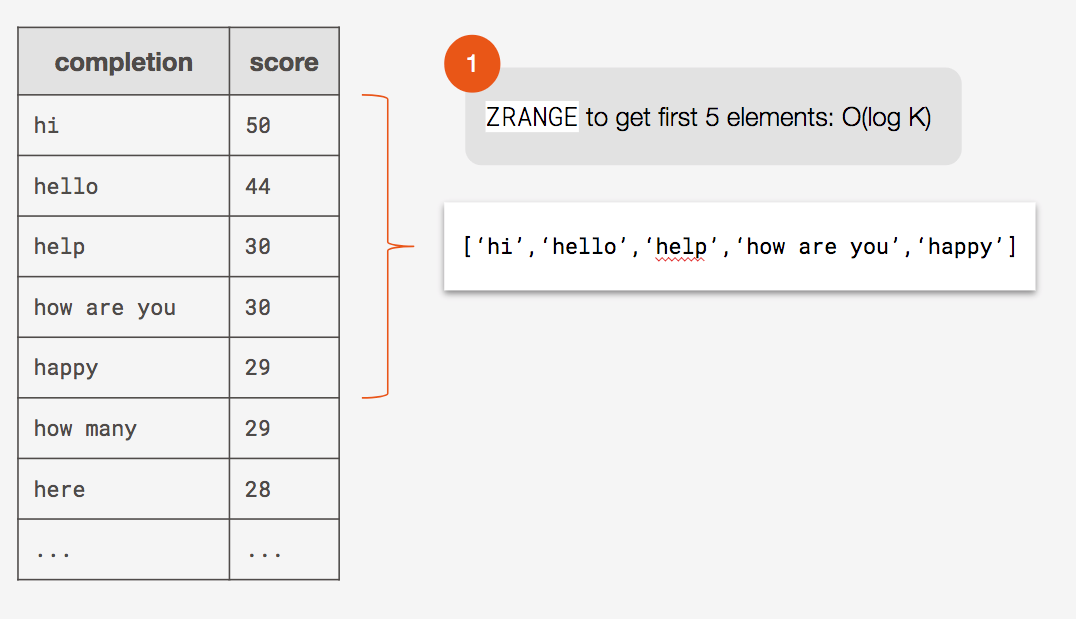
Using the Redis ZRANGE command, searching for suggestions would happen in O(log K) time. Not quite as efficient as the list, but still extremely fast, especially if we limit K.
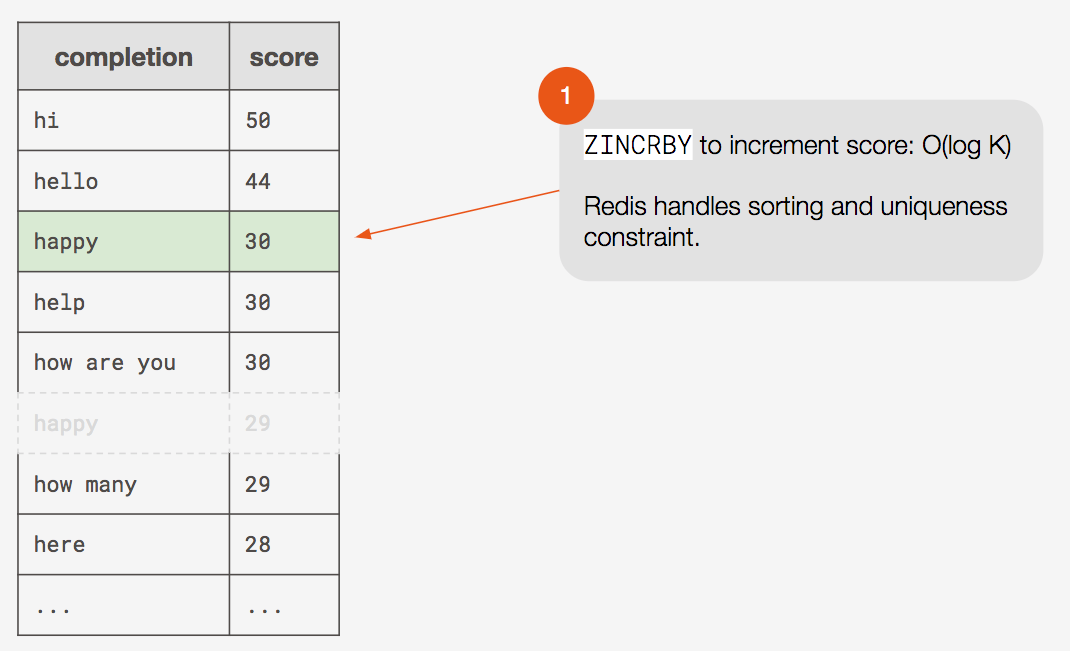
Now let’s look at the increment logic. In most cases, we can accomplish this in a single command! We simply issue a ZINCRBY command to increment the score of a completion. In Redis, sorted sets are implemented under the hood with a skip list data structure, so this update happens in O(log K) time.
In summary, the many benefits of using sorted sets include: fewer round trips to Redis, less chance of concurrency issues, smaller payloads, a uniqueness guarantee, and non-blocking updates. Sorted sets also allow us to maintain the ordering of completions at the database level. This is faster than taking care of order in our application. Search is technically slower than the list, as it is O(log K) rather than O(1). However, logarithmic time is still extremely fast, especially when we limit K. Because of all the above considerations, we ultimately chose to use sorted sets to store completions.
Maintaining Bucket Limit (K)
As we discussed, incrementing a score in a Redis Sorted Set is straightforward. We can simply use the ZINCRBY command. If the completion specified already exists in the sorted set, its score will be incremented. If the completion specified does not exist yet in the sorted set, it will be added.
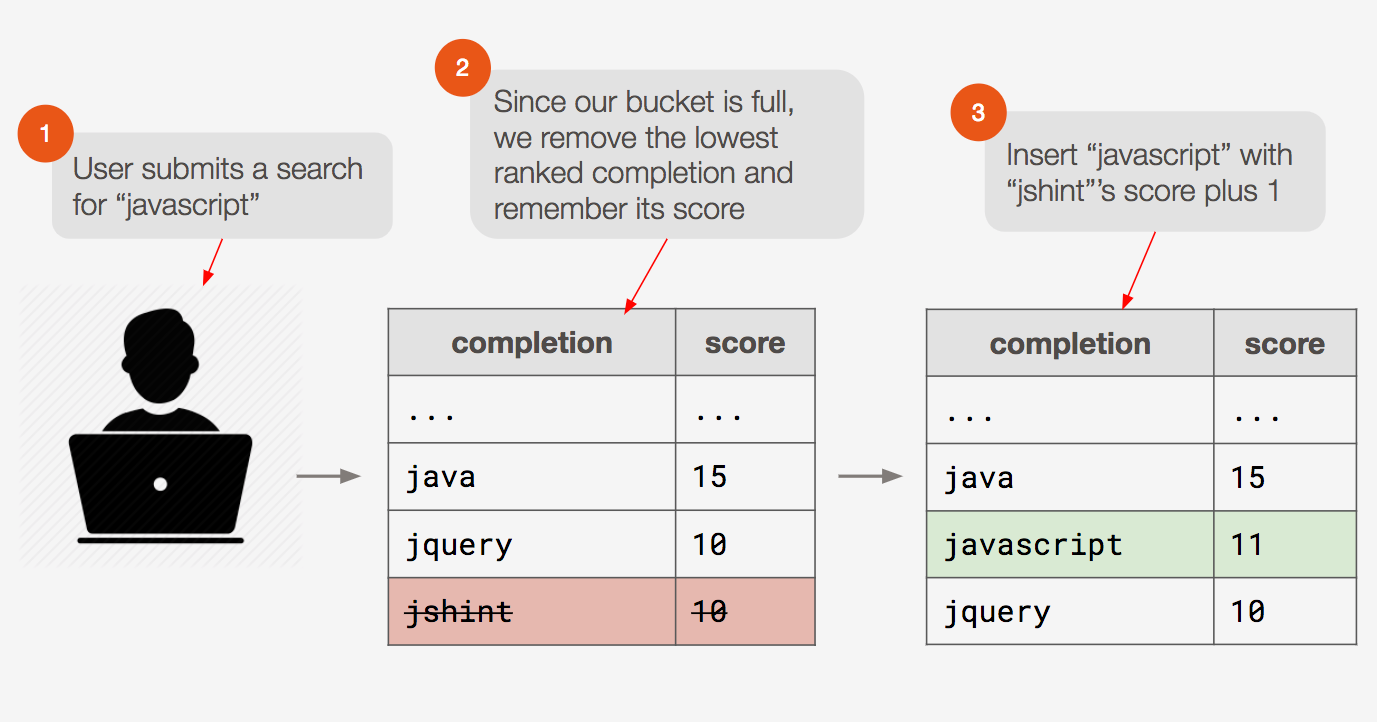
Remember though that we decided to place a limit on K (the number of completions in a bucket). So we need to have logic in our application to maintain the bucket limit. Here we are indebted to Salvatore Sanfilippo, the creator of Redis, who suggested an algorithm to do this in his blog. The procedure is as follows:
When the bucket is full and the completion is not yet in the bucket, remove the completion with the lowest score.
Add the new completion with the removed completion’s score plus 1.
Why use the removed completion’s score plus 1? Simply put, it ensures that a new completion will not be immediately replaced by a subsequent new completion. This is important because if users continue to search for a new completion, we need to provide a way for that completion to be able to rise to the top suggestions. Adding a new completion with the removed completion’s score plus 1, ensures that each new completion gets a shot to rise to the top.
Additionally, we value the recency of queries and this algorithm reflects that. Inserting a new completion with the removed completion’s score plus 1 gives a “boost” to recent queries. This lets us give more weight to fresh queries over stale queries, which helps us return more relevant suggestions to the user.
Persistence Strategy
Now that we had a way to efficiently store, rank, and search our data, the next question we asked was, “what if we run out of memory?” Redis is a completely in-memory database, and as our user base expands and our data grows larger, we will eventually exceed what we can fit in memory.
Our operating assumption is that memory gets more expensive over time, and not all prefixes need necessarily be available in memory at all times. As such, we can treat Redis in a cache-like manner by setting an LRU policy in Redis, so that Redis will hold the most recently used prefixes, and evict the least recently used prefixes when maximum memory has been reached.
To act as the long-term system of record we decided to use MongoDB for hard disk persistence. Whenever we write to Redis, after writing, we serialize the sorted set into MongoDB (therefore Redis is more than just a cache for us as we still rely on it to perform part of our application logic, e.g. maintaining order and ranks).
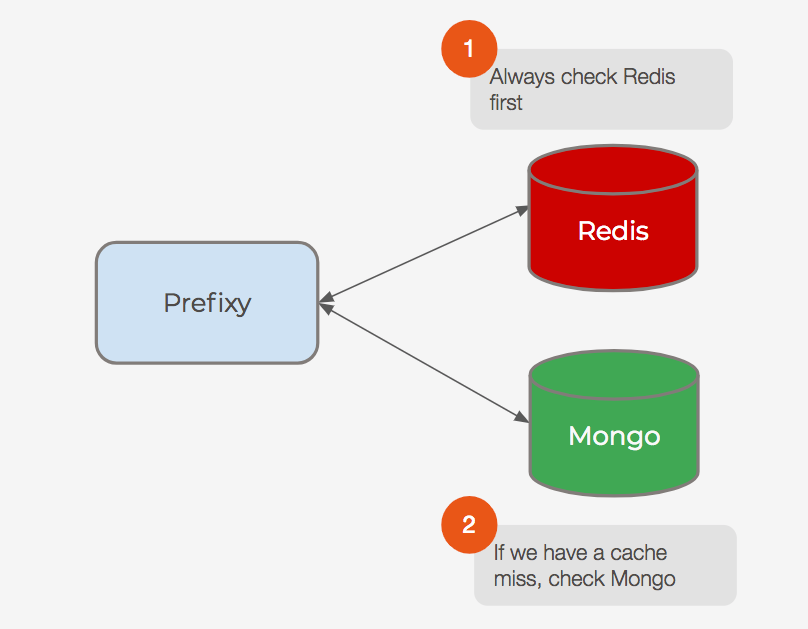
Using this model, now when we perform a search, we check Redis first, which will usually have our data (due to the efficacy of the LRU policy). In the case it doesn’t, we check MongoDB, which has the complete set of prefixes.
Why MongoDB
We chose MongoDB primarily for the fact that its key-document metaphor mapped nicely to the key-value setup we utilized in Redis. By serializing the sorted set of completions as a document and storing it with its prefix in MongoDB, the persistence process is relatively seamless. Further, being able to index prefixes to enable binary search for quick retrieval of documents and collections for multi-tenancy (more on that soon), made for a nice enough fit that we didn’t spend much incremental time evaluating other options.
Also in manually testing the response time of MongoDB with a flushed Redis cache (which meant every prefix query had to check with MongoDB since Redis was empty), the suggestions were still perceived (subjectively) as being returned instantaneously. Obviously this is an area we would like to do more testing of, especially under load, and is part of our future plans.
Working with MongoDB - Search
Although most of the time we can return results from a single call to Redis, we have to load data from MongoDB whenever we have a cache miss.
In case our result comes up empty, it’s possible that it got kicked out of Redis at some point and is sitting in MongoDB. In which case we update Redis with whatever data we have in MongoDB for that prefix before attempt to query Redis again.
By utilizing async/await we ensure that Redis is updated before we return our results.
Working with MongoDB - Increment
Whenever we make a change in Redis we wait for it to finish before persisting the change to Mongo. This is because Redis takes care of sorting logic for us.
After the promise for the changes into Redis returns, we then persist that prefix and its updated completions into MongoDB.
Again, by taking advantage of chaining promises and using async/await, we ensure that our changes are successfully persisted to MongoDB.
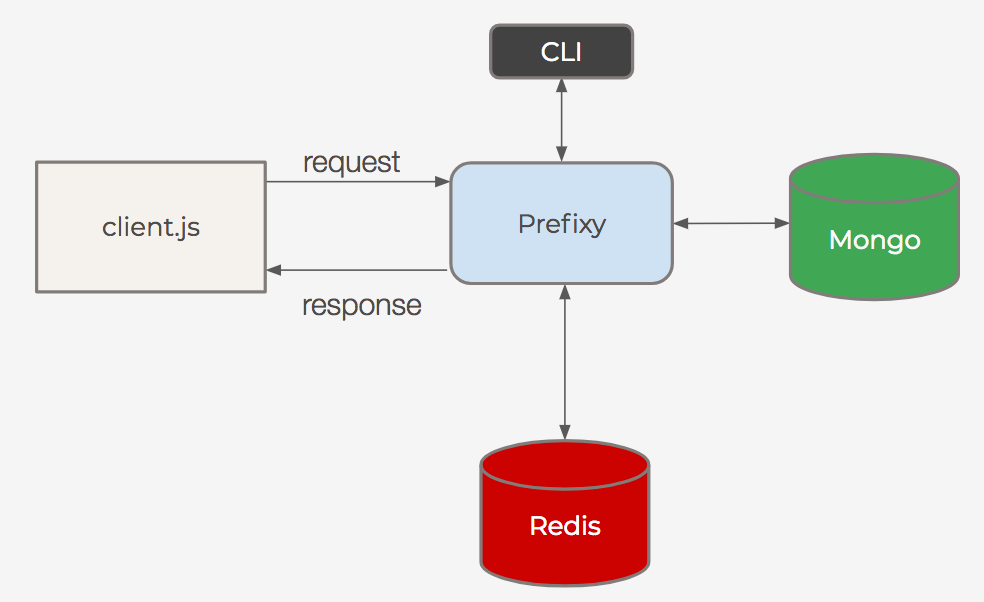
System architecture
Our system architecture so far looks like this:
Building the service
The next goal of our project was to expand our system into a hosted service that can support multi-tenancy. We wanted to create an easy-to-use service that other developers can use to simply setup autocomplete on their web apps.
Authentication setup
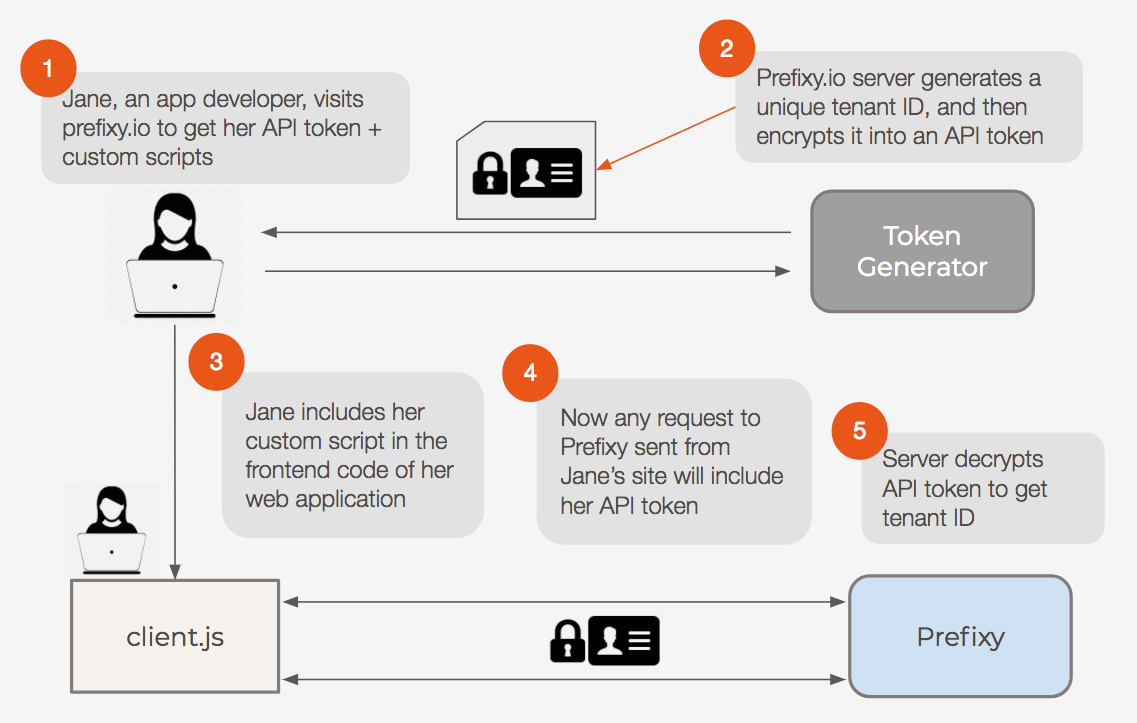
To implement the service, we added a Token Generator server to our system. We set it up so that the Token Generator server and Prefixy server both share a common secret. This means that the Prefixy server can decrypt any tokens encrypted by the Token Generator server.
When a developer requests it, the Token Generator generates a unique tenant ID for her. The tenant ID is then encrypted into a unique JSON web token (JWT). Finally, the token is included in a custom script that initializes the frontend javascript client.
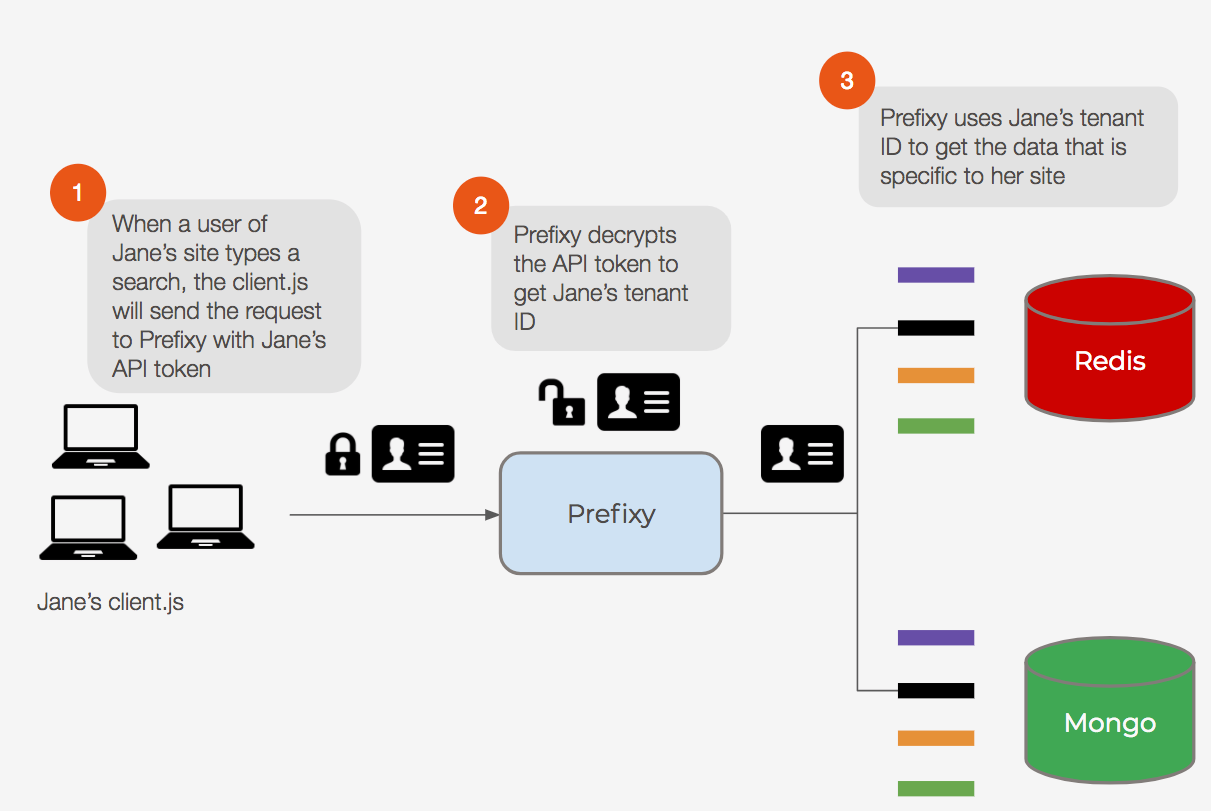
Now the developer can copy and paste the custom generated script. She can include the script in the frontend code of her web app. Now, requests to Prefixy from her app will include her unique JWT. Our Prefixy server can then decrypt the JWT to get the developer’s unique tenant ID.
But how do we use the tenant ID to implement multi-tenancy on the backend? Good question! We use the tenant ID for namespacing our data.
Multi-tenancy in Redis
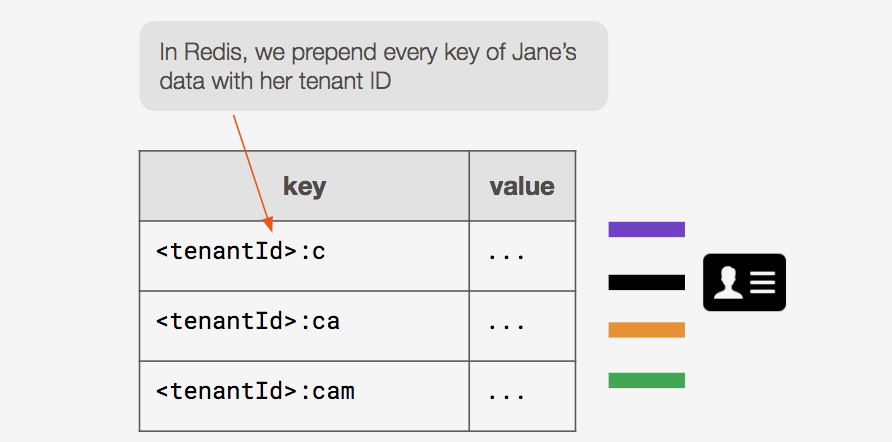
In Redis, we prepend every key of a developer’s data with her tenant ID. So on the backend, all of our Redis keys look like this: <tenantId>:<prefix>.
Now whenever a search request from the developer’s app comes in, we prepend her tenant ID to the search query. The query will now be in the right format (e.g. <tenantId>:<prefix>), and we can simply do a one-to-one key/value lookup.
For increments, the input we’re working with is a completion. We need to increment that completion’s score for every single prefix that it belongs to. So we slice up the completion into all of its possible prefixes. Then we simply prepend the app developer’s tenant ID to each sliced up prefix. Now we can perform our increment logic for the completion and each of its prepended prefixes.
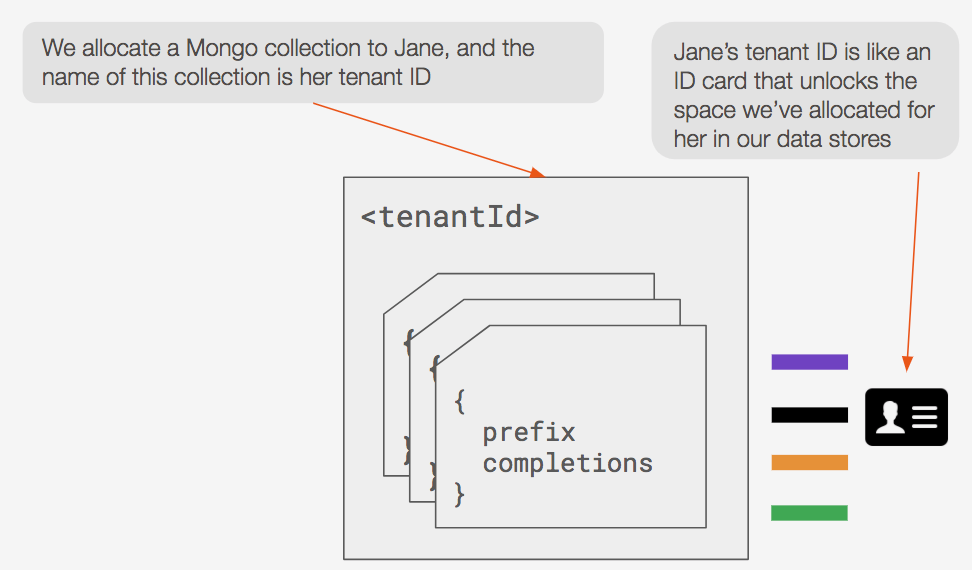
In MongoDB, we allocate a collection for each tenant ID. Collections are provided to us by MongoDB as a built-in way to namespace our data.
Now we can call the findOneAndUpdate method on a collection, in order to insert data into a particular collection. This method ensures that all of the app developer’s data is inserted only within the context of her own allocated collection.
For searches in MongoDB, we can simply chain the find method off the appropriate collection. Now the search will be namespaced under the appropriate collection.
And the same goes for really any MongoDB operation. For instance, to delete a prefix in MongoDB, we call the findOneAndDelete method on the relevant collection.
Client.js
As mentioned earlier, our frontend client is setup to talk to the Prefixy remote server. In order to fetch suggestions, we set up an event listener which listens for any typing being done on the search box.
Whenever this event is fired, the client makes a GET request to the appropriate API endpoint on our Prefixy server. At this time, the client passes along to our Prefixy server the prefix query, or sequence of characters so far that the user has typed. The client also passes along the JWT that was embedded into the script. Now our Prefixy server has everything it needs to fulfill the request.
Once the suggestions come back, the callback pattern is used to invoke the draw method. This method takes each suggestion and appends a corresponding list item to the dropdown list of suggestions.
Similarly, in order to increment a completion’s score, we set up an event listener which listens for any time a user submits a search query.
When this event is fired, the client makes a PUT request to the appropriate API endpoint on our Prefixy server. At this time, the client passes along the completion to be incremented. And the client also passes along the JWT embedded into the script. Now our Prefixy server will take care of the rest and we can simply exit the function, since there’s nothing else we need to do after the user submits their search query.
As of now, we hard code L and K to numbers that we consider to be optimal for the vast majority of use cases. For L, or the max number of chars of prefixes stored, that number is currently 15. And for K, or the max number of completions stored for a given prefix, that number is currently 50.
While these numbers work, we want to eventually allow the app developer to specify L and K if they so choose. It’s impossible for us to predict every possible use case someone might want to use Prefixy for, so giving the app developer the option of customizing L and K would be a nice feature to have.
Scaling Redis to minimize cache misses, and benchmarking persistence strategy
Recall that if we run out of memory, we evict the least recently used prefixes in Redis but still keep them in MongoDB. In the event that a user does search for an evicted prefix, we get the prefix from MongoDB and put it back into Redis. Now whenever someone searches for the same prefix again, we’ll be able to get it for them straight from Redis.
Right now, Prefixy is technically still in beta mode. We currently have 25MB of RAM for Redis and 496MB of hard-disk space for MongoDB, giving us a 20:1 ratio of hard disk space to memory. With this ratio, suggestions already appear to return near instantaneously and therefore we have not yet done any testing to find the ideal ratio of memory to hard-disk space.
However, we do hope to gain many more users within the coming weeks and months. In case Prefixy does experience a massive upsurge in popularity, we know we’ll need to perform extensive benchmarking in order to determine a suitable ratio of memory to hard-disk persistence. Tuning the app in this way will allow us to keep the response time low, even when we’re under heavy load from many users.
Scripting Redis to reduce network requests
Currently, we have a few places in our application logic where we make multiple network requests. For instance, incrementing the score of a completion takes multiple network requests. We also perform multiple network requests in order to “reinstate” an evicted prefix that a user has searched for.
We’re okay with these multiple network requests, since incrementing is a write operation which we’re not optimizing for. And as long as we keep an ideal ratio of memory to hard-disk space, reinstating an evicted prefix is an operation that will only happen rarely.
However, as a further optimization we could eliminate these multiple network requests entirely by using Redis Lua Scripting. Lua Scripting is a way to add functionality to Redis without writing C code. Doing this would allow us to push a lot of our complicated application code to the Redis server. The upshot would be fewer network requests as well as simplified code within our application. A win-win in our books, plus it would give us a convenient excuse to dig into a new programming language which is always fun!
API rate limiter
Another optimization we can make is to rate limit our API. This would prevent malicious users from sending too many requests to our servers in a short period of time. For example, let’s say that we can reasonably set an upward bound of typing speed at 7 characters per second. This means we could set a limit of 7 QPS per user / IP address to keep our service from being overloaded.
We’ll also need to decide if we want to stay free forever or if we eventually want to move to a tiered pricing model. This decision will affect our rate limit quotas. For the time being however, we hope to offer Prefixy as a free service for as long as possible.
Questions?
Feel free to reach out to us about any questions you have about the project. Each of us on the Prefixy team is currently looking for new work opportunities, so we’d be happy to hear from you if we would be a good candidate to join your team!
Auto Complete with Redis - This post by Salvatore Sanfilippo, the creator of Redis, demonstrated the feasibility of using Redis to power autocomplete, and was a crucial source of inspiration for the idea of using Redis Sorted Sets and how to handle the ranking logic.
Prefix Hash Tree - This paper demonstrates the idea of distributing a trie over a Distributed Hash Table. While our use case was different in that we were not distributing a trie, it bolstered our idea of mapping a trie to a hash.




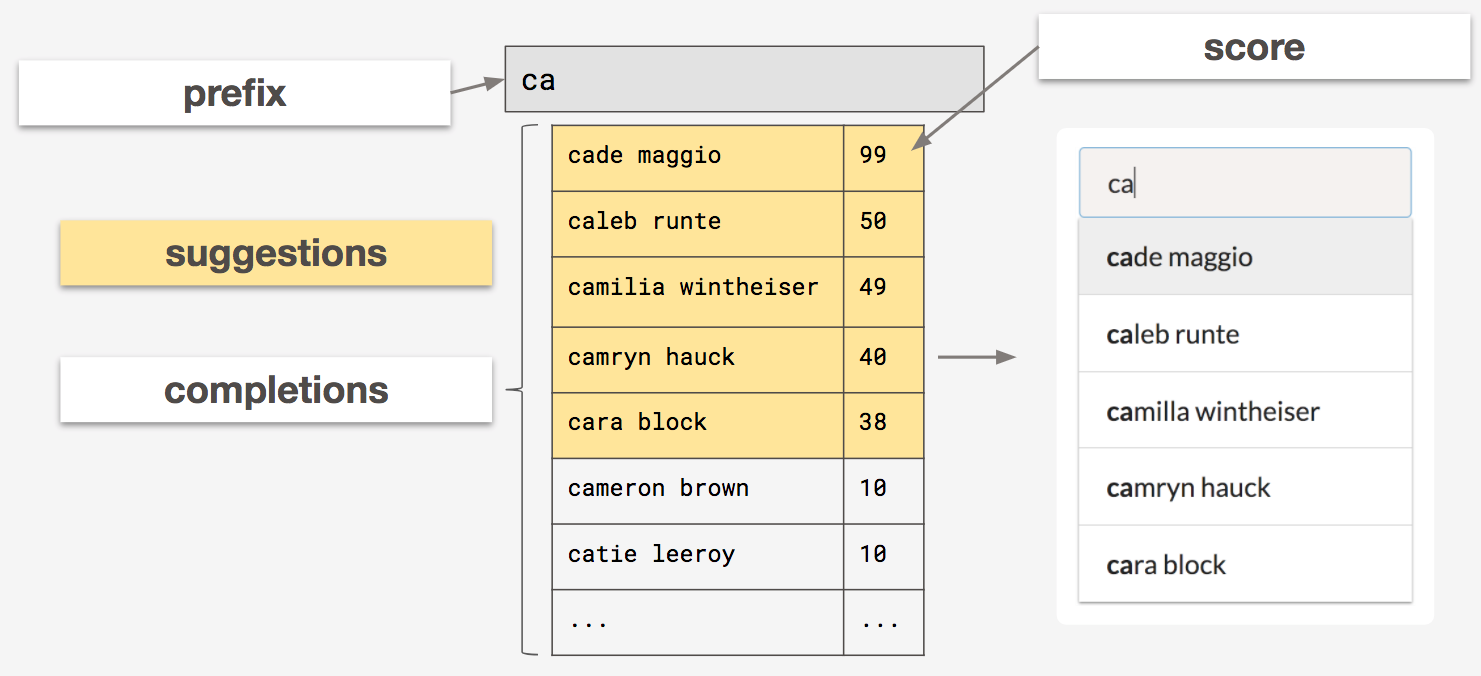

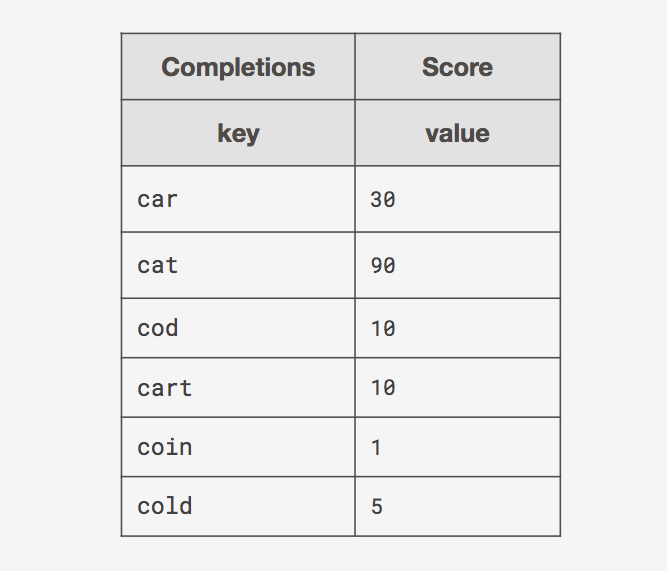
 *some scores omitted for presentation purposes
*some scores omitted for presentation purposes